Story Time
Speech to Text (STT) has always been a bit broken for me. Humans can understand me well but STT generates funny outputs and it eventually becomes frustrating. For example, “testing” gets transcribed as “kes king”.
My designer friend Sumit started vibe coding a WhisprFlow/Granola alternative and he shared me the DMG to test. I kind of knew it won’t work well, but no harm in giving it a try again and to my disappointment it was not that great either.
This made me wonder every app is moving towards voice integration, I recently saw the same in Claude Code, and it’s obviously faster to speak than type. So I thought of figuring a way to get this working for me. The answer: record a bunch of audio, fine-tune Whisper and it would be amazing. Reality - not so straightforward.
Before And After
| Example | Ground Truth | Base Whisper Turbo | Fine-tuned Whisper Turbo |
|---|---|---|---|
| 1 | The quick brown fox jumped over three lazy dogs near the river bank. | The quick brown box jump over three days ago at Snare the Riverbank. | The quick brown fox jumped over three lazy dogs near the river bank. |
| 2 | A bright moon lit the quiet village road after midnight. | A bright moon lit the quake village rogue after the midnight. | A bright moon lit the white village road after midnight. |
| 3 | We drove across twelve bridges before reaching the city center. | We drove across twelve bridges before reaching the Seki Center. | We drove across twelve bridges before reaching the city center. |
Choosing And Recording A Dataset
Spent some time with Claude and ChatGPT to find a good balanced dataset that could capture the problems in my speech patterns, and landed on Harvard Sentences. It consists of 72 lists of 10 sentences each, 720 sentences total where each sentence takes ~2.8 seconds, totalling ~33 minutes of audio. LLMs were of the opinion it was too little for fine-tuning, but my theory was: if humans can understand me ~90-95% of the time, 30 minutes should be a decent start.
Curation
Opened Claude Code and asked it to build me a recording tool. I gave it the Harvard sentences as input and it made a clean web UI that shows me one sentence at a time for recording. It also post-processed the files to WAV at 16kHz sampling as required by Whisper.
The whole process took roughly 2 hours from building to recording all 720 sentences. Once done, I pushed it to Hugging Face for storage.
First Attempt: Whisper Large
I started with Whisper Large because my friend had that included in the DMG he sent me, so looked like a good starting point.
The initial idea was quite simple: make the model pass through the training data and it will learn the patterns. But the Unsloth guide I was following mentioned PeFT LoRA, which I had no clue about, so I did some research and was amazed by the idea. You don’t have to fine-tune the whole 1.6GB model, just add an adapter and train the adapter. Fast, efficient, works on Colab. I was sold.
Whisper-v3-large -> Training Data -> LORA -> Adapter -> Fine Tuned Model -> CoreML Model
Unsloth - Please fix your article naming, I ignored this twice as it mentioned text-to-speech
Measuring Result
All ASR (Automatic Speech Recognition) models measure something called WER (Word Error Rate). I ran my Harvard sentences dataset through the base model and it scored 27% WER. Now you can see why all STT tools are unusable for me.
The First Results
1st run - max_steps=60, lr=1e-4, 1 epoch
WER dropped instantly from 27% to 15% with just 60 steps, then plateaued. This took about 5 minutes and I could already see a big improvement - I was hooked.
2nd run - num_train_epochs=10, lr=5e-5
WER dropped to 9% but validation loss was climbing, meaning the model was overfitting.
Played around with the numbers with Claude for a while and landed on this run:
3rd run - num_train_epochs=5, lr=1e-5
| Step | Training Loss | Validation Loss | WER |
|---|---|---|---|
| 50 | 2.8517 | 2.3652 | 27.4744 |
| 100 | 2.3737 | 2.1784 | 24.0614 |
| 150 | 2.1636 | 1.9048 | 20.4778 |
| 200 | 1.4450 | 1.4194 | 20.1365 |
| 250 | 0.9385 | 1.0925 | 16.8941 |
| 300 | 0.9135 | 0.9767 | 15.1877 |
| 350 | 0.8882 | 0.9181 | 14.3344 |
| 400 | 0.7462 | 0.8889 | 13.8225 |
| 450 | 0.7540 | 0.8767 | 13.8225 |
| 500 | 0.6900 | 0.8647 | 13.1399 |
| 550 | 0.8393 | 0.8448 | 12.9692 |
| 600 | 0.4855 | 0.8388 | 12.1160 |
| 650 | 0.4973 | 0.8514 | 10.7508 |
| 700 | 0.2550 | 0.8629 | 10.7508 |
| 750 | 0.2673 | 0.8616 | 10.4095 |
| 800 | 0.2513 | 0.8600 | 10.7508 |
Good convergence, stable loss reduction. I was happy here and decided to export this model as CoreML for real-world testing.
Note: Apple ARM chips have a dedicated Neural Engine for ML tasks. Models need to be in CoreML format to run on it.
Took ~70 mins on my M1 Pro to convert to CoreML. Loaded it in my friend’s app and saw a big improvement in output quality, but it was slow. Each inference was taking 3-5 seconds. The culprit was the model size: 1.5B parameters is quite large for an older MacBook.
A bit of research led me to the Turbo model, which is distilled from large and much smaller (800M parameters) without much performance degradation.
Second Attempt: Whisper Turbo
Same setup, just changed the model name from whisper-v3-large to whisper-v3-turbo. I started with high expectations of seeing < 10%, but the model started with 53% WER (much worse than Large’s 27%). I still let it continue.
The run ended with WER struggling to drop below 50%. Fine-tuning was actually degrading performance. Did a lot of back and forth with the config but nothing helped.
Claude’s conclusion - Turbo is a distilled model — it was compressed to be fast at standard English by removing the internal complexity that makes fine-tuning flexible. For standard accent adaptation it works fine, but speech sound disorders require deep acoustic-to-phoneme remapping that needs the full model's capacity
Insights
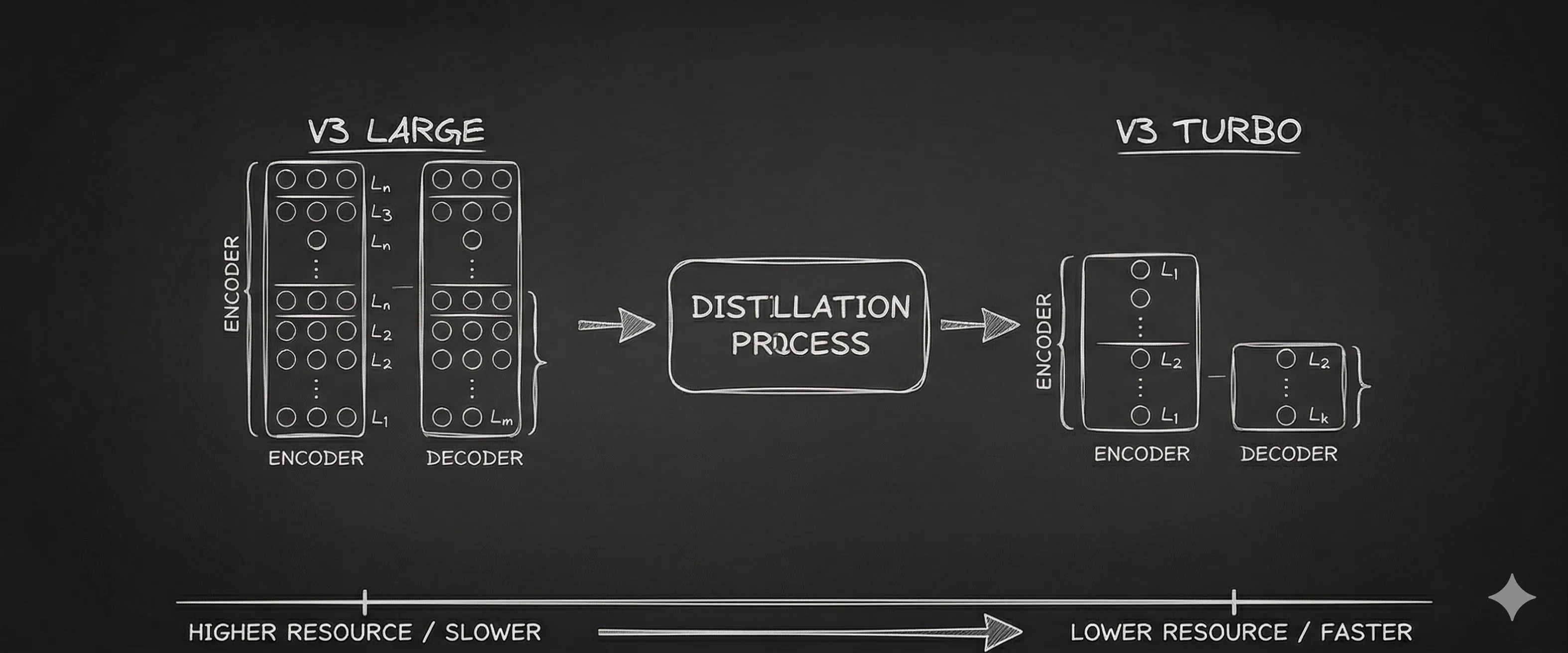
Whisper has two components: Encoder and Decoder. The encoder converts audio to tokens; the decoder converts tokens to text. In v3-turbo, the number of layers is reduced, but not equally across both components.
I was fine-tuning both encoder and decoder weights, but do I need to? A quick chat with Claude helped me understand that the decoder can stay frozen since it’s just converting tokens to text. The real work of adapting to my speech is in the encoder. With only 4 decoder layers, any attempt to fine-tune may have been destabilizing the model, which explains the 53% WER we saw earlier.
What Finally Worked
Around this point I also stopped using Unsloth for Turbo. I ran into issues like max_seq_length errors and cases where the model ended up with zero trainable parameters. Since Turbo is only about 800M parameters and fits comfortably on a Colab T4, I switched to plain transformers + peft and removed one layer of weirdness from the setup.
I updated the config to freeze the decoder weights and only train the encoder. Here’s the result:
| Step | Training Loss | Validation Loss | WER (%) |
|---|---|---|---|
| 100 | 2.7737 | 2.9873 | 26.11 |
| 200 | 0.8632 | 0.9783 | 11.43 |
| 300 | 0.3165 | 0.4686 | 8.70 |
| 400 | 0.1252 | 0.2542 | 7.85 |
| 500 | 0.1243 | 0.2194 | 6.83 |
| 600 | 0.1175 | 0.2066 | 7.00 |
| 700 | 0.0320 | 0.1954 | 6.83 |
| 800 | 0.0437 | 0.1939 | 6.66 |
| 900 | 0.0198 | 0.1945 | 6.48 |
| 1000 | 0.0487 | 0.1961 | 6.83 |
| 1100 | 0.2725 | 0.1959 | 6.48 |
| 1200 | 0.0220 | 0.1943 | 6.66 |
The WER steadily dropped from 26.11% to 6.48%. The curve made sense, training loss fell, validation loss stayed stable
Takeaways
- Dataset of 33 minutes of audio looks tiny but is enough to produce a real shift in performance
- Whisper Large gave early proof of concept, the struggle with Turbo was probably due to smaller decoder. Freezing it made a huge difference for me.
- Unsloth has great notebooks for spinning up and testing things, good starting point but didn’t work well with freezing decoder.
What’s Next
I ran the 720 sentences through my fine tuned model to find out where it still struggles. There are a lot of patterns which I can see, so I am thinking to record 100-200 specialised sentences around those problems and then try to push WER even down. Overall I enjoyed writing parts of this article through my fine tuned model and it’s fun the see it work around 80-90% of the time correctly.
Resources
- Code for the recorder and fine-tuning notebook: GitHub
- Fine-tuned model: Hugging Face
- LoRA Adapter: Hugging Face
A lot of the code is refactor by LLM and I haven’t tested it, so please create issue/email if it doesn’t work.
