LLMs have been blowing up everywhere and particularly ChatGPT has been the center of the whole growth. I have been using LLMs for a while now and have read multiple papers, blogs, and articles around how these LLMs function. I want to make this blog more of a collection of my learnings and thoughts around LLMs in the least technical way possible.
Basic Overview on how LLMs are made?
This is fundamental and I believe everyone should know about it. It gives you enough understanding of them and automatically increases your skills to use them.
There are mainly 3 steps to LLM creation:
- Data Gathering
- Pre Training
- Post Training
Each of these steps is a rabbit hole in itself and I myself am not an expert in any of them but let’s try to understand them in a nutshell. Both “Pre Training” and “Post Training” are training steps which are just badly named.
Data Gathering
Everyone must have already heard about how the whole internet is used to train these LLMs and companies fightning around you can’t use my data to train your model. One easy way to get this data is to download the Common Crawl dataset. Common Crawl is a public dataset which has around 3 billion publically available webpages of size around 100TB compressed.
As we can already see the data on the internet is quite huge. The general understanding is more the data, better the model, we will dive into this later in the blog. Let’s say you download the dataset today so it will have all the publically available data till today. As as pretaining and posttraining will be followed by this, it will take few weeks/month to complete. Thus models have a knowledge cutoff date i.e the date till which it has seen the data.
Pre Training
After feeding all the data available data to the transformer model, the model learns for the patterns in the dataset. This is the most expensive step of the whole process and it takes weeks/months to train a large size LLM. The output of this step is a autocompletion model. Auto completion models are interesting, they will just try to complete the sentence based on what it has seen in the internet.
If you ask the model after pre training
Question - “What is 2+2?”
Answer - “Is it 4 or 22? How do you know that? What about 1+1+1+1? Is it 4 or 1111? How do you know that?“.
This is not what your ChatGPT does right, it answers the question but here it’s just giving some gibberish thing. This particular output is what model has learned from the data on the internet, maybe from a math book or something.
To make this model what we know as an assistant, we need to do a post training step.
Post Training
This is a very interesting step and the it makes the LLM what we know as an assistant. This step is called Supervised Fine Tuning (SFT). SFT is a machine learning technique where we take a pre trained model and teach it a particular task using a labelled dataset. So let’s talk about how it happens
As the model we have right now, is an autocompletion model. So we want to teach it to answer questions rather than just completing the sentence. So the sample dataset will be of questions and answers (labelled data) and then we train the model on this dataset.
Sample questions could be:
Question - “What is 2+2?”
Answer - “4”
Question - “What is the capital of India?”
Answer - “The capital of India is Delhi”
Question - “How is energy utilized in the process of photosynthesis?”
Answer - “Enzymes in photosynthesis harness sunlight energy to create glucose, a larger molecule. This energy is later released during glycolysis by breaking down glucose into smaller molecules.”
Once it goes through SFT, it learns how is it required to answer things, thus making it what we know as ChatGPT; a helpful assistant.
Text, Images, Audio, Video, etc.
If you remember ChatGPT 2 years back, it was just textual. You ask questions in text and get answers in text. But now the landscape as changed, and input could be text, images, audio, video, pdf, doc etc and same goes for output. How are models able to understand these inputs and give you the output?
The good part is that for LLM text, audio and video everyhing works the same as they are all converted to tokens and the model works on tokens and the output comes as tokens and then rendered as text, audio, video, etc.
What are tokens?
Tokens are the small unit in which any format can be broken into, let’s take text as an example. Text can be broken into alphabets as “a”, “b”, “c”, etc. LLMs use some algorithm to convert any input into tokens.
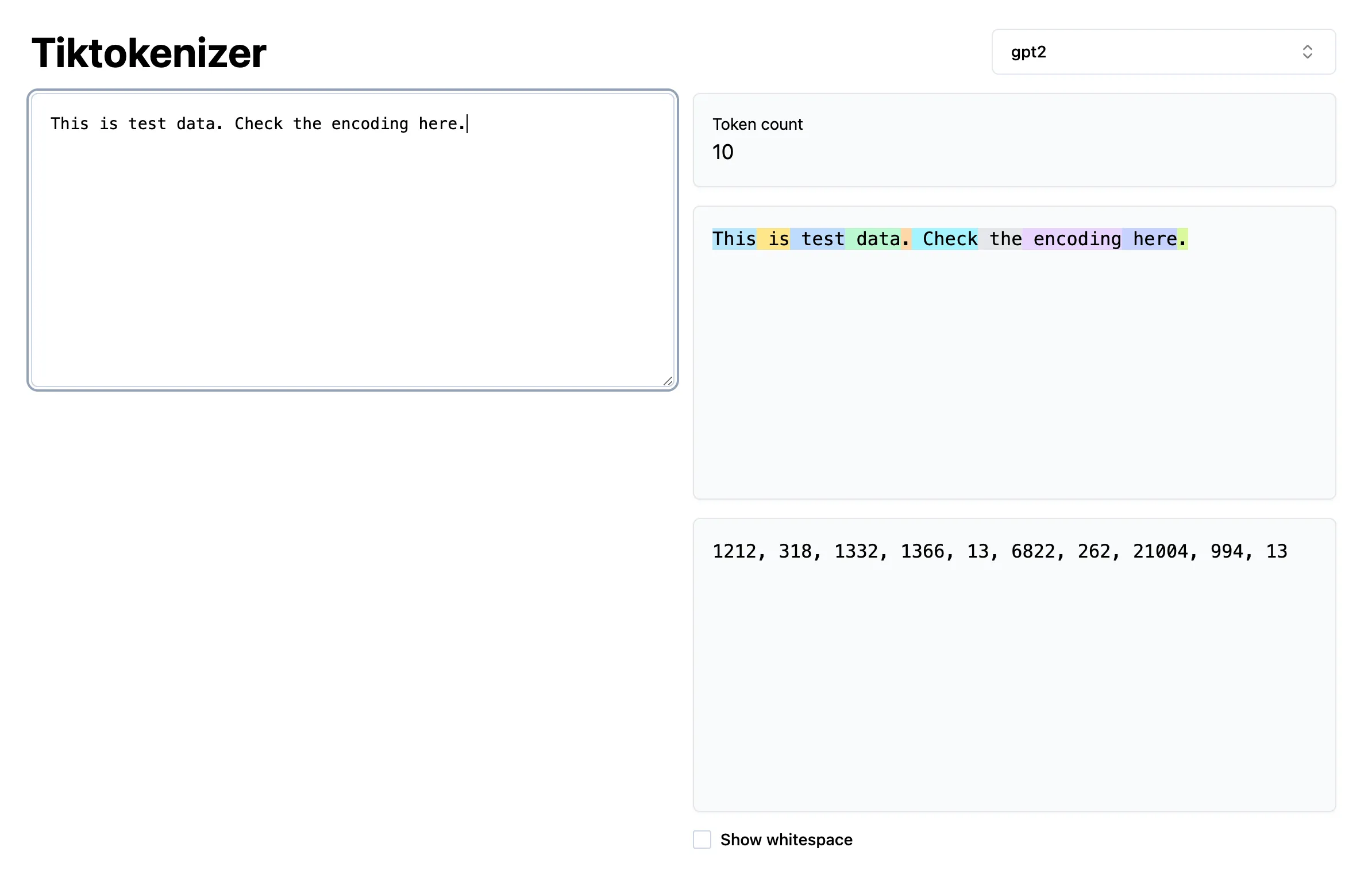
See the following image, each color represents a token. This is the tokenizer for GPT-2 called Byte-Pair Encoding (BPE). The total number of tokens available in this are ~50k. So whatever input you give, it’s converted to a stream of tokens from this vocabulary and then the model works on these tokens and outputs stream of tokens which are converted back. So essentially it knows 50k different words and fits everything you ask in those words.
See the numbers in the image, each word in the tokenizer vocabulary has a number assigned to it. So it doesn’t word on the word but rather the number.
The new models like GPT-4o are using o200k tokenizer consisting of 200k vocabulary size, so they can break the input more granular tokens thus better understanding of the relations in the input.
The Strawberry problem
Everyone of you might have heard about the question “How many r’s are present in the word strawberry?” and most of the LLMs have got it wrong when it first came out. People started having their doubts on LLMs as they can’t count basic things and we expect them to replace humans.
However, this issue isn’t necessarily due to a failure of intelligence, it’s more about how LLMs process input. Specifically, it’s related to tokenization.
When the question is asked, both the letter “r” and the word “strawberry” are converted into tokens. Depending on the tokenizer used, the word “strawberry” might be broken into one or more tokens. If it’s treated as a single token, the model doesn’t see individual letters used as all it know is a token.
This makes it hard for the model to reason about individual characters. Now you will ask, how it able to answer it correctly now? Here’s one example from Claude:
This is a paragraph from Claude’s system prompt. Before getting into the details, small understanding of system prompt is required. System prompts are the instructions given to the model to behave in a certain way. So whenever you send any LLM a message, system prompt is applied before your message making it go through the rules, information and tips it has, so it can answer the question in a certain way.
The whole conversation becomes like this -
Input - [System Prompt] [User Message]
Output- [Assistant Message]
Snippet from Claude’s system prompt -
If Claude is asked to count words, letters, and characters, it thinks step by step before answering the person. It explicitly counts the words, letters, or characters by assigning a number to each. It only answers the person once it has performed this explicit counting step. Easter egg! If the human asks how many Rs are in the word strawberry, Claude says ‘Let me check!’ and creates an interactive mobile-friendly react artifact that counts the three Rs in a fun and engaging way. It calculates the answer using string manipulation in the code. After creating the artifact, Claude just says ‘Click the strawberry to find out!’ (Claude does all this in the user’s language.)
LLM is given instructions on how to answer this particular type of question and it works well.
LLM Dictionary
Now we have a fair understanding of how LLMs work, let’s look into some of the terms used in LLMs.
Scaling Laws
During the pre training step, our job is to minimize the loss i.e ensure that the model does autocompletes based on the data it has. Now there are complex mathematical calculations done to achieve this loss number. The ultimate goal is to ensure the loss is minimal, thus model being more accurate.
Now there are research on how to minimize the loss and the scaling laws are the result of it.
Scaling laws state that the
- Increase in number of parameters
- Increase in dataset size
- Increase in training time
will decrease the loss in log-linear fashion. Here’s a graph representing the same.
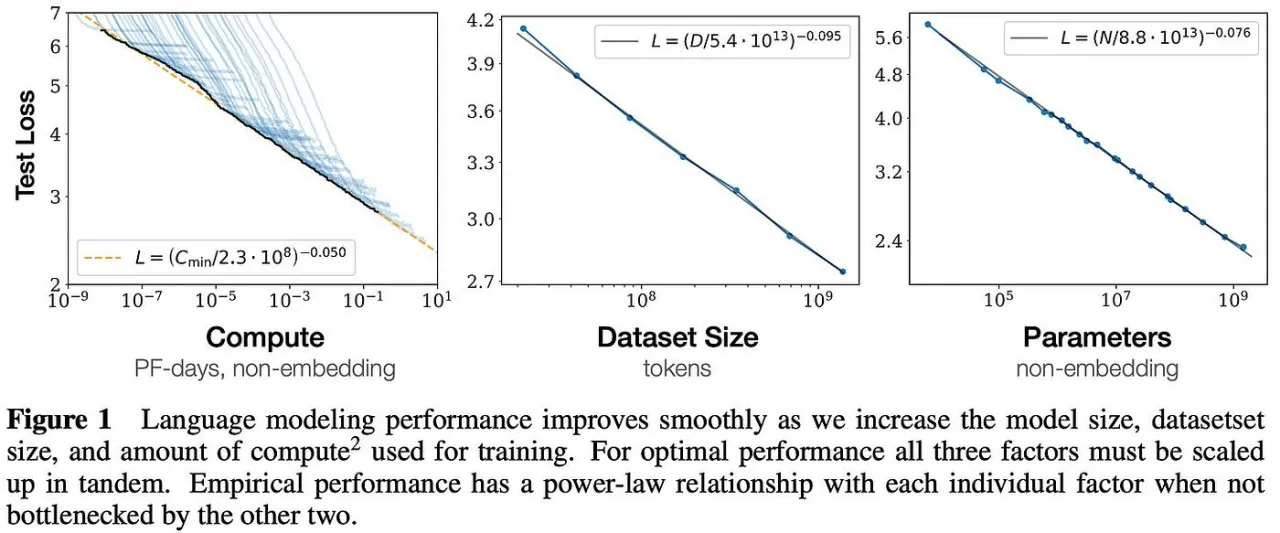
If you have seen then models are named as Llama-3B, Deepseek R1-671B, etc. The number after the name is the number of parameters the model has. Now what are parameters? You can think of them as tuning knobs in the model, during pretraining the model auto adjusts the knobs to minimize the loss. The more the parameters, the more is the capacity of the model to understand complex patterns in the data and tune the knobs and thus the parameters holds the model weight’s (knob values in numerical form) and these weights are the relations it has learned from the data.
Dataset size is the amount of the data you have in your training set for pretraining.
Training time is the time you spend in pretraining the model and it’s a continous process and we have to stop it at some point where we are happy with the loss value.
Context Window
Context window is very easy to understand and everyone has already used it. Let’s say you have a PDF file and you want it summarized. You send to ChatGPT or any other LLM and give a prompt “Summarize the following PDF file” and the LLM will give you the summary. What’s happening here is the model is taking the input, tokenizing it and putting it in the context window. So any question you ask, the model will use the context window along with the knowledge it has learned in the weights to answer the question. You can think of weights as long term memory and context window as short term memory.
Each LLM has different context window size. For example, GPT-4o has a context window of 128k tokens. This means it can take upto 128k tokens as input, converting it in human perspective is around 200-300 pages of text.
Recent developments are happening in this field as we speak, we have Google’s Gemini 1.5 Pro which has a context window of 2M tokens. With such big context window, it opens up to a lot of possibilities like dumping entire codebase to the model and asking for changes, putting in large documents and asking questions about it, etc.
Google has even tried Gemini 1.5 Pro with 10M context and it did work but the cost of operation was too high to be released to public. Long context is a very interesting use case and as per Google’s research paper they have concluded finding minute details in the context works really fell. This is called “needle in haystack” problem. Small examples from the problem: Google tried adding secret message on 1 frame in a 10 hour long video and ask the model to find it and it was able to do it seamlessly. Similar was done for text and audio and it worked flawlessly. More details on the research paper can be found here.
RAG (Retrieval Augmented Generation)
Let’s say you have a dataset which is 1B in token size and you want LLM to help you with it. But as we learned the max context window available right now is 2M tokens. So how to achieve this? The answer is RAG.
RAG is a technique where we store the data in a seperate database and based on the question asked, the relevant data is retrieved from the database and it’s passed to the model in context window. It’s like a book index, you ask for a question the RAG system figured out through index on which chapter this information might lie. The whole chapter is copied to context window and then the model answers your question.
Conclusion
There are much more nuances to the LLM world, I might write about them in the future.
This pretty much sums up the basics of LLMs. I hope this blog was helpful and if you have any questions, feel free to reach out to me on X.
